Create files Chunks and vectors from APEX

Search for a command to run...
No comments yet. Be the first to comment.
Context is one of the most important things when working with AI. That's kind of the agent "memory" during the session. A key part of the context giving the agent instructions on what to use for speci

A new Data Source was included in this release, you can see it when including a new component, it's called "Sample Data" Some components like maps, charts and Calendar have this source type now, that

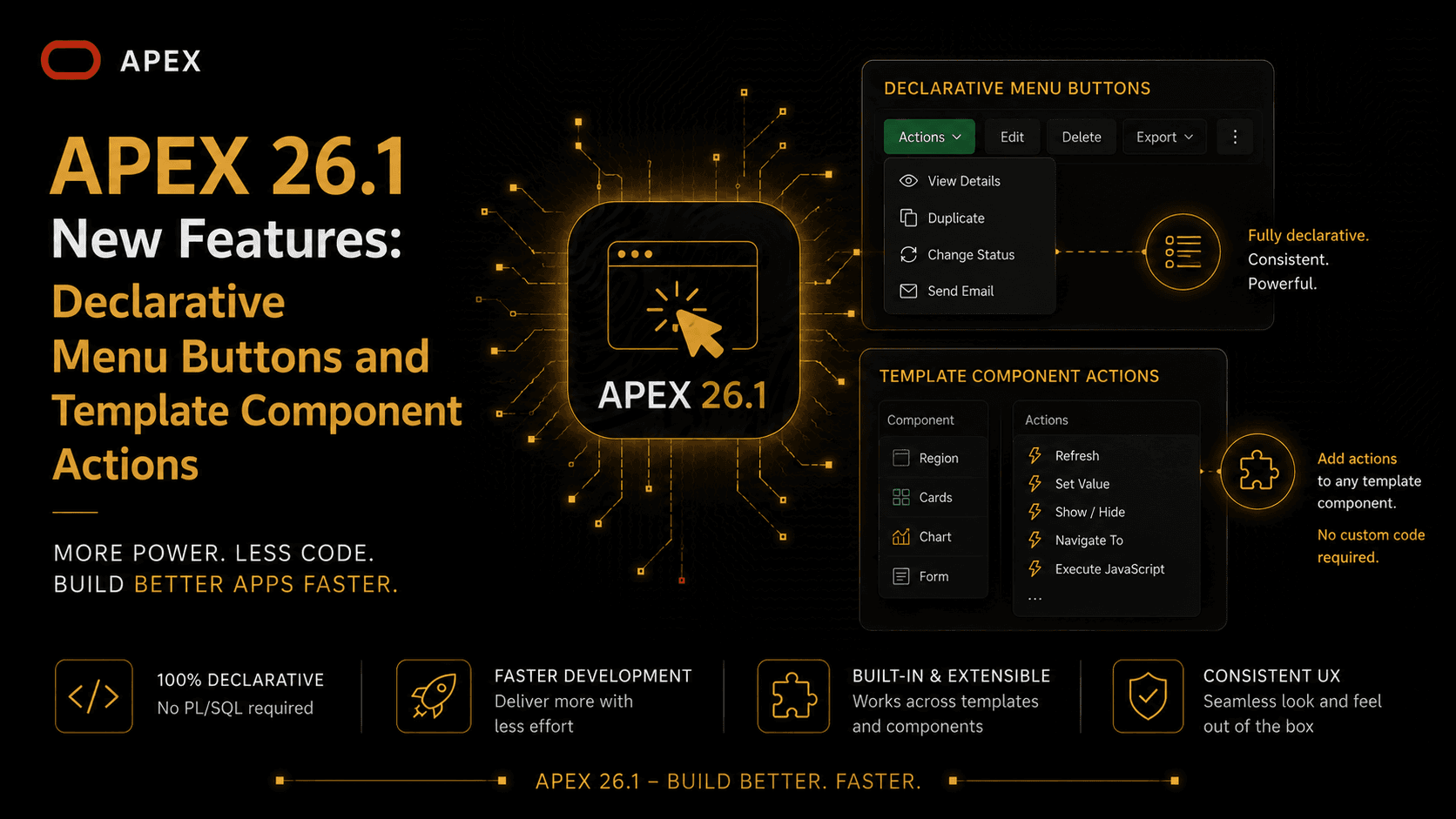
This is a great combination for something the used to take some effort on writing some functions to execute actions on specific rows of an IR, like using a hidden page item, assigning the PK value of
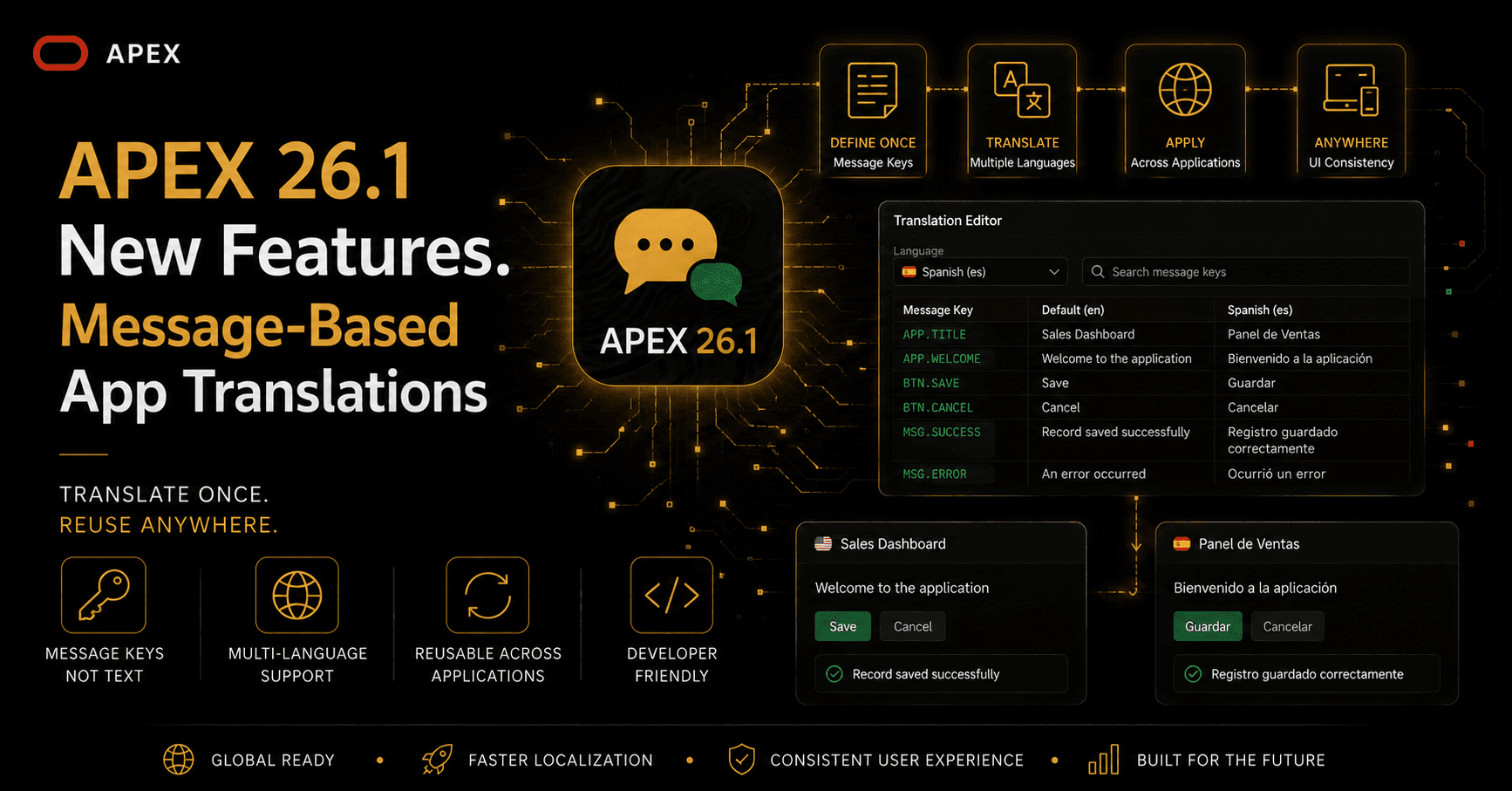
Creation of a parallel translated app is no longer the only way to handle multiple languages in APEX. Now under Globalization Attributes, we can select "Text Message-Based" as Translation Method. On
Recently, I created an APP using APEXlang, (check here). I asked the agent to create a lookup table including columns to store colors and icons, useful to work with status for example. The agent no on

This is a process you could do using OCI features, but if you’d like to manage files from an APEX application, take care of the conversion to vectors and store them your database, it’s quite possible and not that complicated.
What for? let’s say we want to build a RAG assistant using the content of the uploaded files, so this would be an important step.
Is a matter of taking advantage of the DBMS_VECTOR_CHAIN package APIs.
Let’s take as example this page, I uploaded a document into my application and is stored in the RAG_DOCUMENT table:
create table rag_document
( doc_id number generated always as identity
minvalue 1 maxvalue 9999999999999999999999999999
increment by 1 start with 1 cache 20 noorder
nocycle nokeep noscale not null enable
, doc_content blob
, status_code varchar2(30 char) default 'PENDING'
, doc_filename varchar2(500 char)
, doc_mime_type varchar2(500 char)
constraint rag_document_pk primary key (doc_id) using index enable
) ;

The idea is dividing the files in smaller pieces, often called Chunks, so we can later use for generating vector embeddings and vector indexes.
I created a table called RAG_DOC_CHUNK, where I intent to save chunks of the files and their vector representation, the last one in a Vector type column.
create table rag_doc_chunk
( doc_chunk_id number generated always as identity
minvalue 1 maxvalue 9999999999999999999999999999
increment by 1 start with 1 cache 20 noorder
nocycle nokeep noscale not null enable
, doc_id number
, chunkid number
, chunk_content varchar2(4000 char)
, chunk_vector vector
, chunk_offset number
, chunk_length number
) ;
In order to use the functions that allow us generating the embeddings (utl_to_embedding), the onnx model needs to be already uploaded in the database, please refer to: Now Available! Pre-built Embedding Generation model for Oracle Database 23ai
Now, let’s create a simple procedure to read the file, create the chunks and generate the embeddings from the chunk text.
create or replace procedure ingest_files
as
--name of the embedding model
l_model_name varchar2(100):='ALL_MINILM_L12_V2';
begin
--Reads the pending docs to be processed
for docs in ( select doc_id
, doc_content
from rag_document
where status_code = 'PENDING')
loop
--inserts the chunks into the table from a query that will generate them
insert into rag_doc_chunk ( doc_id
, chunkid
, chunk_offset
, chunk_length
, chunk_content
, chunk_vector )
--query generating the chucks and embeddings
select docs.doc_id
, rownum
, ct.chunk_offset
, ct.chunk_length
, ct.chunk_text
-- using utl_to_embedding to generate the vector representation of the text in the chunks
-- notice here the use of the model declared above
, dbms_vector_chain.utl_to_embedding(ct.chunk_text,json('{"provider":"database", "model":"'||l_model_name||'"}')) vector_text
-- vector_chunks is the function to split plain text into smaller chunks
-- Notice it has some parameters that you can change depending on your needs.
-- utl_to_text is used to convert the blob content of the file into plain text
from vector_chunks( dbms_vector_chain.utl_to_text(docs.doc_content)
by words max 300 overlap 15
split by newline normalize all) ct;
--Finally, just mark the file as Active to be used for vector search
update rag_document
set status_code = 'ACTIVE'
where doc_id = docs.doc_id;
end loop;
commit;
end ingest_files;
/
Now, we can create a button to execute the procedure from the page. The button’s behavior will be “Submit Page”

and also a process that will be executed just when our new button is clicked. The process Source is the procedure ingest_files we just created.

Now, the page looks like this:

By clicking the button, after a the process is completed, well see the file status changed to “Active”


If we query the chunk table, we can see there the text and vector representation.

The process could take some time if we’re working with heavy files. This works as a simple example, but we could take it from here and transform this into a background process. Maybe a topic for another post :)